I’ve worked on a good number of projects, one of them being NC Lang , a language that one of my friends, noClaps , has been designing for a while.
Over in that project, I’ve been working on a proposal for something called NCA. Hell, at the time of writing, you can find the shitty AI RFC draft over there. But if you don’t feel like reading that whole proposal, the general idea is a lower-level, abstract, IR-ish language that lets developers write code that interoperates at a level close to assembly, while also being able to talk to and work with NC code natively.
It also has some concepts that step away from the norm, which is the fun part.
Here, you can have a look at an example. This is not set in stone:
pub fn memcpy(dst: addr, src: addr, n: uptr) -> addr, nc { entry: %zero = const.uptr 0 jmp loop(%zero)
loop(%i: uptr): %done = cmp.ge.uptr %i, n br %done, exit, body(%i)
body(%i: uptr): %src_p = addr.add src, %i %x = load.u8 %src_p %dst_p = addr.add dst, %i store.u8 %dst_p, %x %next = add.uptr %i, 1 jmp loop(%next)
exit: ret dst}While looking into NCA and trying to figure out whether it was something we actually needed, versus something I just thought would be cool to have, I started splintering off into a slightly different line of thought.
I wanted to learn to write more Zig, and the question became: what if I tried a PoC for this idea, but in Zig, and with a more direct native-code focus?
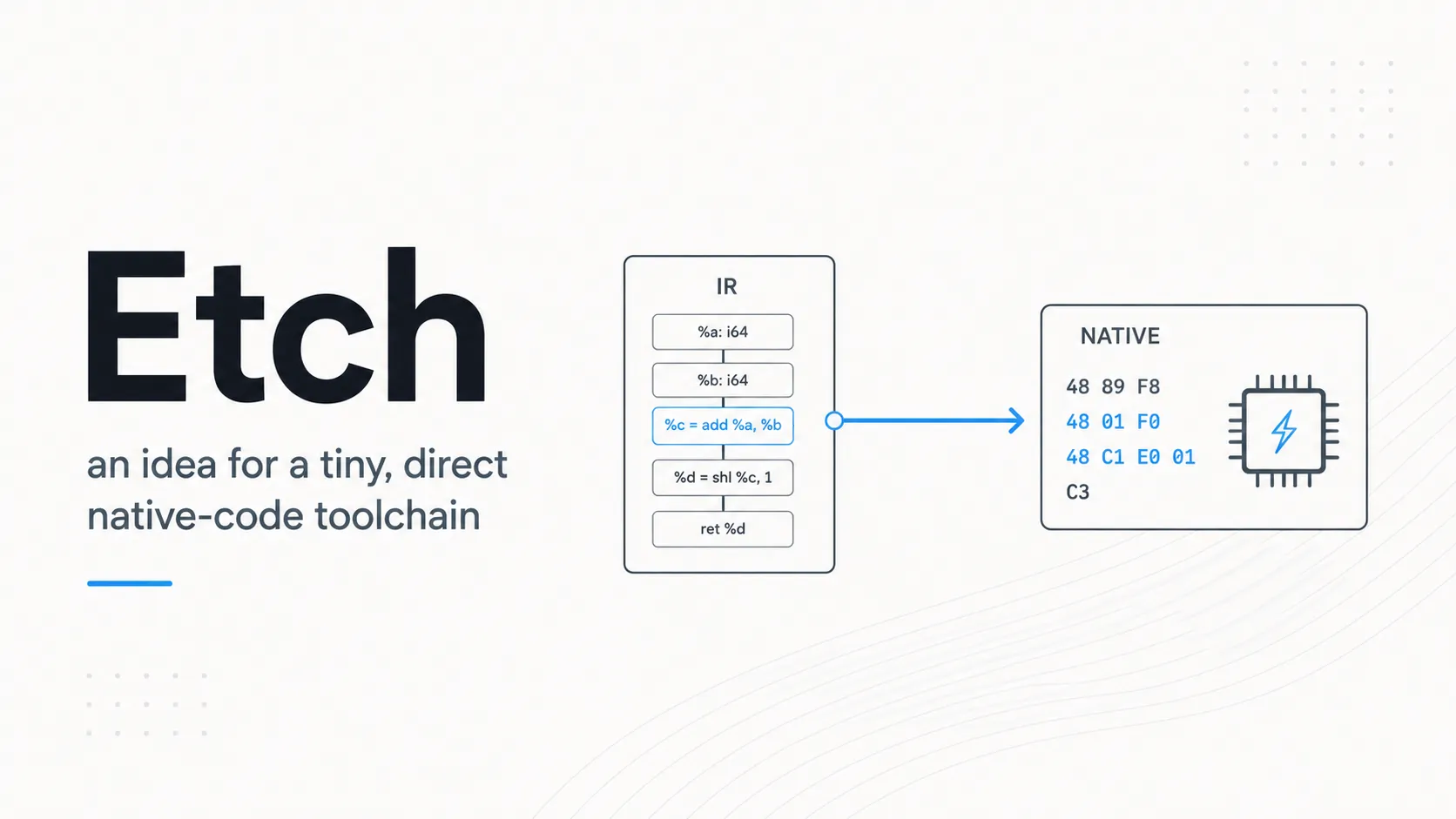
That’s how Etch got drafted.
The basic idea
Etch is a simple idea: what if you could describe a program in a small, typed, intermediate/lower-level language, then have a pure Zig library turn it directly into a real native binary?
We already know this kind of thing is possible from GCC , Go ’s assembler/toolchain work, LLVM , and a bunch of other projects. But most of these tools come with some kind of tradeoff. They are huge, not very friendly to embed, tied to their own language ecosystems, or they eventually shell out to platform tools somewhere in the pipeline. Even LLVM, which is basically the main guy in the field, can be a pain to work with from something like Zig.
The main goals for Etch are pretty blunt:
- No LLVM.
- No system assembler.
- No system linker.
- No shelling out to platform tools just to create an object file.
Just Etch in, and native bytes for the target OS out.
That pretty easily defines the crude shape of Etch.
Etch cannot, and should never, be something like Rust, Zig, C, Go, or Swift. The core idea is that you make it a backend for your language, not that you write your entire application in it as if it were a normal high-level programming language.
For example, NCC could use an Etch builder API and produce binaries using Etch, rather than writing individual assembly files and asking a system toolchain to build them for whatever system it happens to be running on.
Etch is the part that owns the lower-level work: verification, lowering, register allocation, object writing, linking, and getting the final bytes into the shape the target OS expects. The frontend still owns the actual language.
The three ways to write Etch
As mentioned above, Etch has a few different levels, which can be worked with through a builder API or a .etch file.
The first level is a standardized portable IR. The gist is that this IR works across all possible Etch targets using virtual/fake registers, which Etch then maps to the proper registers and instructions for the selected target. These cover the generic operations you would expect: integer arithmetic, loads, stores, calls, branches, vector operations, and the usual lower-level building blocks.
The next level is target-tuned IR. You’ll see an example below, but the idea is that this extends the IR with architecture-specific operations. For example, on an x86_64 CPU variant with AVX-512, we can target specific optimizations and features that we cannot express in a fully standardized portable set of code. Same thing for AArch64, where we might want to build around NEON or SVE.
The third and final way to write is the obvious one: assembly.
No matter how good Etch is, it will almost certainly miss some feature or capability that a certain CPU architecture supports. AI assistance may make that gap smaller, but it will definitely still exist. So in that obvious use case, Etch needs to provide a viable and usable escape hatch without making the rest of the system give up on what it still needs to do.
This leads into the fun area: how the fuck does this work?
Well, that’s easy: functions can have variants.
module "etch_memcpy_demo"
targets = [ { arch=x86_64, os=linux, abi=sysv, features=[sse2, cmpxchg16b] }, { arch=x86_64, os=linux, abi=sysv, features=[avx2, bmi2, popcnt] }, { arch=x86_64, os=linux, abi=sysv, features=[avx512f, avx512bw, avx512vl] },
{ arch=aarch64, os=linux, abi=aapcs64, features=[v8_0] }, { arch=aarch64, os=linux, abi=aapcs64, features=[v8_0, sve] },
{ arch=riscv64, os=linux, abi=lp64d, features=[c, a] }, { arch=riscv64, os=linux, abi=lp64d, features=[c, a, v] }]
link_mode = static_pielibc = nonelibc_link = nonesystem_dependency_policy = forbidden
export @etch_memcpy as "etch_memcpy"
func @etch_memcpy(%dst: ptr, %src: ptr, %n: i64) -> ptr cc=etch { ; Portable baseline. This is the correctness fallback. ; Any target can lower this, and Etch may still optimize it. default { entry: br ^loop(i64 0)
loop(%i: i64): %more = icmp.ult %i, %n cbr %more, ^copy_byte, ^done
copy_byte: %sp = gep i8, %src, %i %dp = gep i8, %dst, %i %b = load i8, %sp, align=1 store %b, %dp, align=1 %next = iadd nuw %i, i64 1 br ^loop(%next)
done: ret %dst }
; Generic target-tuned x86_64 version. ; Lets Etch select/register-allocate target-specific vector ops. variant target={arch=x86_64, os=linux, abi=sysv, features=[sse2]} { entry: br ^wide(i64 0)
wide(%i: i64): %remaining = isub %n, %i %has16 = icmp.uge %remaining, i64 16 cbr %has16, ^copy16, ^tail
copy16: %sp = gep i8, %src, %i %dp = gep i8, %dst, %i %v = load <16 x i8>, %sp, align=1 store %v, %dp, align=1 %next = iadd nuw %i, i64 16 br ^wide(%next)
tail: br ^tail_loop(%i)
tail_loop(%j: i64): %more = icmp.ult %j, %n cbr %more, ^tail_byte, ^done
tail_byte: %sp1 = gep i8, %src, %j %dp1 = gep i8, %dst, %j %b = load i8, %sp1, align=1 store %b, %dp1, align=1 %j1 = iadd nuw %j, i64 1 br ^tail_loop(%j1)
done: ret %dst }
; AVX2 raw variant: whole-function assembly alternative. ; Good for hot paths where we want exact instructions. variant target={arch=x86_64, os=linux, abi=sysv, features=[avx2]} raw { """ inputs: dst = rdi src = rsi n = rdx
output: rax = dst
clobbers: rcx, r8, ymm0, memory, flags
preserves_stack_pointer: true provides_own_prologue_epilogue: true x87_empty_on_entry: true
mov rax, rdi xor rcx, rcx
.Lavx2_loop: cmp rdx, 32 jb .Lavx2_tail vmovdqu ymm0, ymmword ptr [rsi + rcx] vmovdqu ymmword ptr [rdi + rcx], ymm0 add rcx, 32 sub rdx, 32 jmp .Lavx2_loop
.Lavx2_tail: test rdx, rdx jz .Lavx2_done
.Lavx2_tail_byte: mov r8b, byte ptr [rsi + rcx] mov byte ptr [rdi + rcx], r8b inc rcx dec rdx jne .Lavx2_tail_byte
.Lavx2_done: vzeroupper ret """ }
; AVX-512 raw variant. ; Variant scoring should prefer this over AVX2 when the emit target supports it. variant target={arch=x86_64, os=linux, abi=sysv, features=[avx512f, avx512bw, avx512vl]} raw { """ inputs: dst = rdi src = rsi n = rdx
output: rax = dst
clobbers: rcx, r8, zmm0, k1, memory, flags
preserves_stack_pointer: true provides_own_prologue_epilogue: true x87_empty_on_entry: true
mov rax, rdi xor rcx, rcx
.Lzmm_loop: cmp rdx, 64 jb .Lzmm_tail vmovdqu8 zmm0, zmmword ptr [rsi + rcx] vmovdqu8 zmmword ptr [rdi + rcx], zmm0 add rcx, 64 sub rdx, 64 jmp .Lzmm_loop
.Lzmm_tail: test rdx, rdx jz .Lzmm_done
; Build a tail mask with low n bits set. mov r8, 1 shlx r8, r8, rdx dec r8 kmovq k1, r8 vmovdqu8 zmm0 {k1}{z}, zmmword ptr [rsi + rcx] vmovdqu8 zmmword ptr [rdi + rcx] {k1}, zmm0
.Lzmm_done: vzeroupper ret """ }
; AArch64 portable-width tuned variant. variant target={arch=aarch64, os=linux, abi=aapcs64, features=[v8_0]} { entry: br ^wide(i64 0)
wide(%i: i64): %remaining = isub %n, %i %has16 = icmp.uge %remaining, i64 16 cbr %has16, ^copy16, ^tail
copy16: %sp = gep i8, %src, %i %dp = gep i8, %dst, %i %v = load <16 x i8>, %sp, align=1 store %v, %dp, align=1 %next = iadd nuw %i, i64 16 br ^wide(%next)
tail: br ^tail_loop(%i)
tail_loop(%j: i64): %more = icmp.ult %j, %n cbr %more, ^tail_byte, ^done
tail_byte: %sp1 = gep i8, %src, %j %dp1 = gep i8, %dst, %j %b = load i8, %sp1, align=1 store %b, %dp1, align=1 %j1 = iadd nuw %j, i64 1 br ^tail_loop(%j1)
done: ret %dst }
; AArch64 SVE scalable-vector variant. ; Scalable vectors lower only when the selected target supports SVE. variant target={arch=aarch64, os=linux, abi=aapcs64, features=[sve]} { entry: br ^sve_loop(i64 0)
sve_loop(%i: i64): %active = mask.whilelt %i, %n %any = mask.popcount %active %more = icmp.ne %any, i64 0 cbr %more, ^sve_copy, ^done
sve_copy: %sp = gep i8, %src, %i %dp = gep i8, %dst, %i %v = predicated.load <vscale x 16 x i8>, %active, %sp, align=1 predicated.store <vscale x 16 x i8>, %active, %v, %dp, align=1 %step = vscale.bytes(i8) %next = iadd nuw %i, %step br ^sve_loop(%next)
done: ret %dst }
; RISC-V baseline scalar tuned variant. variant target={arch=riscv64, os=linux, abi=lp64d, features=[c, a]} { entry: br ^loop(i64 0)
loop(%i: i64): %more = icmp.ult %i, %n cbr %more, ^copy_byte, ^done
copy_byte: %sp = gep i8, %src, %i %dp = gep i8, %dst, %i %b = load i8, %sp, align=1 store %b, %dp, align=1 %next = iadd nuw %i, i64 1 br ^loop(%next)
done: ret %dst }
; RISC-V V scalable-vector variant. variant target={arch=riscv64, os=linux, abi=lp64d, features=[v]} { entry: br ^rvv_loop(i64 0)
rvv_loop(%i: i64): %active = mask.whilelt %i, %n %any = mask.popcount %active %more = icmp.ne %any, i64 0 cbr %more, ^rvv_copy, ^done
rvv_copy: %sp = gep i8, %src, %i %dp = gep i8, %dst, %i %v = predicated.load <vscale x 16 x i8>, %active, %sp, align=1 predicated.store <vscale x 16 x i8>, %active, %v, %dp, align=1 %step = vscale.bytes(i8) %next = iadd nuw %i, %step br ^rvv_loop(%next)
done: ret %dst }}Take this pseudocode as the example. Here we can provide a set of variants for a given function, almost like overrides, but for a specific architecture, operating system, ABI, and feature set.
You can drop in a portable fallback with default, then add target-tuned variants for specific CPUs or ISAs, then go all the way down into raw assembly when you want exact instructions. At emit/compile time, Etch picks the best variant for the target being built.
Or, if desired, it could include multiple variants and add runtime logic that analyzes what the host exposes one time, then uses the best path forward from there.
This type of thing is what I think makes Etch fun and cool. You can write portable code easily, then drop lower where and when it matters.
Where this fits
A small programming language could use Etch as its backend. The frontend, say written in Zig, owns the parsing, type checking, language semantics, packages, and user-facing errors. Etch owns the entire lower-level backend: IR verification, lowering, object writing, linking, and native output.
A systems project could also use Etch to throw together small pieces of native code during a build. Maybe it needs a small helper, a bootable image, a UEFI app, a tiny static Linux binary, or just a native object file it does not want to build through a random system assembler.
That is the line I want Etch to sit on. It should be low-level enough to be useful to compiler and systems people, but not so bare that every useful thing requires writing raw assembly by hand.
What Etch is not
The point here is not that Etch should fully replace LLVM.
For one, that would probably be impossible. Etch will more than likely never reach that level. But also, as a project, it should not try to be that. LLVM is so fucking big because it solves a gigantic problem. It has frontends, backends, optimizers, target support, debug-info support, platform weirdness, decades of production hardening, and a giant ecosystem wrapped around it.
Etch is not that.
The point is to carve out a smaller shape: a pure-Zig native-code backend and binary emitter that is direct, embeddable, deterministic, and designed around being pleasant to use from another language implementation.
That also means .etch should not pretend to be a normal high-level language. It can be hand-written, and it should be possible to author a full program in it, but it should still be understood as IR. No package manager. No hidden module discovery. No magical type inference. No language-level standard library. Those are frontend problems.
Etch starts where a frontend has already decided what the program means.
The part I really like
I also really like the idea that Etch is deterministic.
Given the same input, target, allocator, and pinned toolchain, it should output the same bytes. Not “roughly the same binary.” Not “same behavior but different build IDs.” The same bytes.
Even when the input changes, if the logical design is the same, the output should be stable in the places where stability is possible. That kind of thing matters when you’re building toolchains, comparing artifacts, testing compilers, caching builds, or trying to prove that a backend is not doing weird hidden shit behind your back.
That’s the larger idea behind Etch: keep the toolchain small enough to reason about, direct enough to trust, and flexible enough that a language can use it without giving up all the sharp tools that systems programmers still need.
Maybe it turns into a real thing. Maybe it just becomes a good experiment.
Either way, the idea feels worth throwing into the world. Whether I actually open-source it really depends on how much code I can review, how much I can understand Zig, and how much effort I’m willing to put in to a project that I don’t get paid for (lol).