Let’s say you’re building a system — a database, a message broker, a game server, whatever — and you’ve reached the point where HTTP isn’t cutting it. Maybe the overhead per request is too high. Maybe you need persistent bidirectional connections. Maybe JSON parsing is eating your latency budget. Whatever the reason, you’ve decided to design a custom binary protocol over TCP.
This post walks through the decisions you’ll face, roughly in the order you’ll face them. I’ll use examples from Mayfly, a distributed key-value store I’m building as an experiment to see how far AI-assisted development can take a systems project. The protocol spec, architecture decisions, and design work are mine. The implementation leans heavily on AI. It’s been a pretty interesting way to test both the tools and my own understanding of what I’m asking for. I’ll also reference Kafka, Redis, Postgres, MQTT, and Source RCON — protocols I studied before writing my own.
Do You Actually Need a Custom Protocol?
JSON over HTTP works for the vast majority of systems. It’s debuggable with curl, self-documenting, and almost every language has a client library. If your system has moderate throughput, request-response semantics, and no persistent connection requirements, stop here. Just use REST.
A custom binary protocol earns its complexity in specific situations:
- Persistent bidirectional connections. HTTP/1.1 keep-alive is a hack. WebSockets add framing overhead. A raw TCP connection with your own framing is simpler than either, if you need it.
- High message rates where per-message overhead matters. HTTP headers alone can be 500+ bytes. A 12-byte binary header is meaningful savings at 100k messages/second.
- Fine-grained control over framing, multiplexing, or consistency semantics. When the protocol is the interface — like a database wire protocol — HTTP’s request-response model gets in the way.
- Latency sensitivity. No HTTP parsing, no header negotiation, no chunked transfer encoding. Just bytes in, bytes out.
Kafka, Redis, Postgres, and MQTT all went custom for these reasons. The heuristic is simple: if the bottleneck is network overhead, connection management, or framing flexibility, a custom protocol is worth it. If the bottleneck is developer time, it isn’t.
TCP or UDP: The First Irreversible Decision
This choice shapes everything downstream, and you can’t change it later without rewriting your entire networking layer.
TCP gives you a reliable, ordered byte stream. Bytes arrive in order and intact, or the connection dies. The tradeoff is that TCP has no concept of message boundaries — it’s a stream of bytes, not a sequence of messages. Your protocol must define its own framing (we’ll get to that). TCP also means connection setup cost (three-way handshake) and head-of-line blocking (one lost packet stalls everything behind it).
UDP gives you independent datagrams. Each sendto() produces exactly one datagram on the receiving end — if it arrives at all. You get natural message boundaries for free, but you lose ordering, delivery guarantees, and congestion control. If you need any of those, you’re rebuilding them yourself.
The decision framework:
flowchart TD
A[Do you need reliable, ordered delivery?] -->|Yes| B[TCP]
A -->|No| C{Is latency more important<br />than completeness?}
C -->|Yes| D[UDP]
C -->|No| B
B --> E[You handle framing<br />and message boundaries]
D --> F[You handle ordering,<br />retransmission, and congestion]
style B fill:#2d5016,stroke:#4a8c2a,color:#fff
style D fill:#4a1942,stroke:#8c2a7a,color:#fff
- Request-response systems, authenticated sessions, anything where message loss is unacceptable -> TCP. This is most infrastructure software.
- Real-time scenarios where latency matters more than completeness -> UDP. Game state updates, live media, DNS lookups.
For Mayfly — a key-value store where losing a SET acknowledgment would mean silent data loss — TCP is pretty clearly the obvious choice. The rest of this post assumes TCP. The header design principles carry over to UDP, but you’ll need your own sequencing, acknowledgment, and retransmission layers on top.
Designing the Header
Every message starts with the header. Every parser reads it first. Mess it up and you’ll feel it for the life of the project.
The core constraint: the header must be fixed-size and parseable in constant time. No variable-length fields, no conditional parsing. The receiver reads exactly N bytes, extracts every field at known offsets, and knows exactly how many more bytes to read for the payload. This is non-negotiable. If the header can’t be parsed in a single fixed-size read, every parser, logger, and debug tool gets more complex.
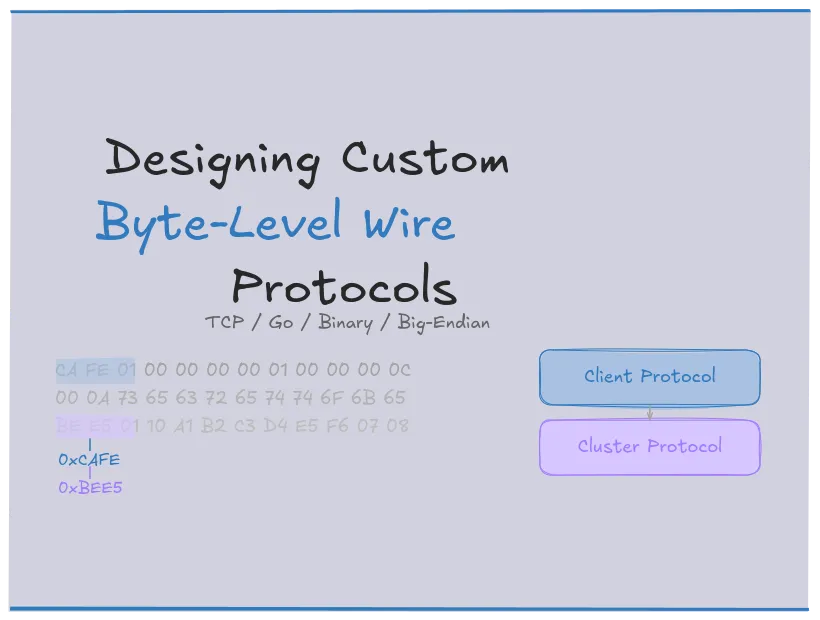
The layout I went with for Mayfly is a 12 byte header:
block-beta
columns 4
A["Magic<br />0xCAFE<br />2 bytes"]:2 B["Version<br />0x01<br />1 byte"] C["Cmd / Status<br />1 byte"]
D["Request ID<br />4 bytes"]:4
E["Payload Length<br />4 bytes"]:4
style A fill:#2d5016,stroke:#4a8c2a,color:#fff
style B fill:#1a1a2e,stroke:#4a4a6a,color:#fff
style C fill:#4a1942,stroke:#8c2a7a,color:#fff
style D fill:#1a1a2e,stroke:#4a4a6a,color:#fff
style E fill:#1a1a2e,stroke:#4a4a6a,color:#fff
Magic Bytes: Protocol Identification
The first bytes of every message are a fixed value that identifies your protocol. When the server reads from a new connection, the first thing it checks is: “Is this my protocol?”
Magic bytes solve two problems:
- Wrong client detection. Someone points a web browser at your database port. The first bytes are
GET /orPOST. Your magic is0xCAFE. Mismatch at byte zero, reject immediately. - Desync recovery during debugging. After stream corruption or a framing bug, you can scan forward byte-by-byte looking for the magic pattern and attempt a header parse from that offset. It’s crude, but it works.
Two bytes gives 65,536 possible values. Enough to avoid accidental collisions while small enough to not waste space. Pick something hex-readable: CAFE, DEAD, F00D, BEE5. You’ll see it thousands of times in packet captures, and recognizable magic makes spotting your protocol’s traffic instant.
What to avoid: 0x1603 (TLS ClientHello), 0x4854 (HT from HTTP), 0x5353 (SS from SSH), and 0x0000 (zero-initialized memory shouldn’t look like valid traffic).
If your system will eventually have multiple protocols — say, one for clients and one for internal cluster communication — give each a different magic number. In Mayfly, I went with 0xCAFE for client traffic and 0xBEE5 for cluster traffic. A cluster gossip message accidentally hitting the client port fails at byte zero instead of being misinterpreted as a malformed SET command. Belt and suspenders with the separate ports, but overall a nice and cheap insurance.
Version: Future-Proofing in One Byte
The most important byte for long-term protocol health, and the one most often omitted in v1.
The version byte sits right after the magic. Server checks it immediately: do I speak this version? No? Error, close. No heuristics, no “well the payload looks like v2 so maybe…”
Source RCON has no version field. Every implementation deals with ambiguity about whether a particular message format quirk is intentional or a bug. Good luck adding one retroactively.
RCON’s full header:
10 00 00 00 # Size: 16 (little-endian, not network byte order)01 00 00 00 # ID: 103 00 00 00 # Type: 3 (SERVERDATA_AUTH)6D 79 70 61 # Body: "mypass"73 73 00 00 # + double null terminatorThree fields. No magic bytes, so a stray HTTP request won’t be rejected at byte zero. No version, so the protocol is frozen at whatever Valve shipped in 2004. The type field uses 2 for both EXECCOMMAND requests and AUTH_RESPONSE replies, so you’re guessing by context.
You have two strategies for version handling:
Client-declares — the version is in every message header, and the server accepts or rejects per-message. Simple, stateless, and what Mayfly currently uses. The downside is that the server must support every version it might receive at any time.
Handshake negotiation — during connection setup, client and server exchange supported version ranges and agree on the highest mutual version. Kafka does this via its ApiVersions request. More complex, but allows gradual version rollouts across a fleet.
Kafka’s ApiVersions handshake on the wire:
# ApiVersions Request (first thing a client sends)00 00 00 1A # Message size: 26 bytes00 12 # API Key: 18 (ApiVersions)00 03 # API Version: 300 00 00 7B # Correlation ID: 12300 0B 74 65 # Client ID length + "test-client"73 74 2D 636C 69 65 6E74The broker responds with every API key it supports and the min/max version range for each. The client picks the highest mutually supported version per API. Every subsequent request includes the API key and chosen version in its header, so the broker knows exactly which parser to use.
For most systems, client-declares is sufficient. Plan for version negotiation from day one. You don’t need to implement v2 yet. You just need the version byte in the header so that when v2 arrives, the parser knows which format it’s reading.
Command / Status: One Field, Two Meanings
This byte does double duty. In a request, it’s the command code (what the client wants to do). In a response, it’s the status code (what happened). Servers see commands; clients see status codes.
Separate fields would waste a byte per message for a value that’s always zero.
Organizing Your Command Space
With one byte, you get 256 possible commands. Sounds like a lot, but it fills up fast once you add data structure operations, admin commands, and cluster operations. You can assign them sequentially (0x00, 0x01, 0x02, …) or group them by category.
Grouping by high nibble is worth the effort:
0x0_ = Core commands (AUTH, SET, GET, DEL, PING, QUIT, ...)0x1_ = Collection ops (LPUSH, RPUSH, LPOP, RPOP, LRANGE, ...)0x2_ = Counter ops (INCR, DECR, INCRBY, ...)0x3_ = Nested map ops (HSET, HGET, HDEL, HGETALL, ...)0x5_ = Admin commands (SNAPSHOT, MEMORY, STATS)0x6_ = Cluster commands (CLUSTER_INFO, CLUSTER_NODES, LEAVE)The payoff is in debugging. When you’re staring at a hex dump at 2 AM and you see command byte 0x31, you instantly know it’s a nested map operation (the 3_ range) — specifically HGET. Without grouping, 0x31 is just “the 49th command” and you’re reaching for the spec.
flowchart LR
subgraph Grouped["Grouped by nibble"]
g1["0x01 -> Core"]
g2["0x10 -> Collection"]
g3["0x31 -> Map"]
g4["0x52 -> Admin"]
end
subgraph Flat["Flat numbering"]
f1["0x01 -> ???"]
f2["0x10 -> ???"]
f3["0x1F -> ???"]
end
style g1 fill:#2d5016,stroke:#4a8c2a,color:#fff
style g2 fill:#2d5016,stroke:#4a8c2a,color:#fff
style g3 fill:#2d5016,stroke:#4a8c2a,color:#fff
style g4 fill:#2d5016,stroke:#4a8c2a,color:#fff
style f1 fill:#4a1942,stroke:#8c2a7a,color:#fff
style f2 fill:#4a1942,stroke:#8c2a7a,color:#fff
style f3 fill:#4a1942,stroke:#8c2a7a,color:#fff
Leave gaps between groups. In the layout above, 0x4_ is reserved for future use. If you need a new category of commands in v2, you have room without reshuffling existing codes.
Reserve 0x00 for AUTH (it should always be the first command after connect), and never use 0x00 as a status code. Zero-initialized memory shouldn’t look like a valid response — if you see a zero status byte, something went wrong.
Status Codes That Help You Debug
Design your status codes to be self-describing without payload inspection. When you see status 0x0A in a wire log, it should tell you something specific:
0x01 = OK0x02 = NOT_FOUND0x03 = UNKNOWN_CMD0x04 = BAD_PAYLOAD0x05 = KEY_TOO_LONG0x06 = VALUE_TOO_LARGE0x07 = SERVER_ERROR0x08 = AUTH_REQUIRED0x09 = AUTH_FAILED0x0A = WRONG_TYPE (e.g., list op on a string key)0x0B = OUT_OF_MEMORY0x0C = TIMEOUT (e.g., cluster quorum not reached)Don’t settle for three status codes (OK, ERROR, NOT_FOUND) and shove the details into the payload. Granular status codes mean your wire logger can decode the outcome without parsing the payload, and clients can branch on the status byte directly instead of string-matching error messages.
For distributed systems, reserve a range for cluster-specific codes. In Mayfly, I reserved 0x10 = MOVED and 0x11 = TOPOLOGY_CHANGED, borrowing the MOVED pattern from Redis Cluster. The idea: when a node receives a request for a key it doesn’t own, it responds with MOVED plus the address of the correct node. The client caches this mapping and sends subsequent requests directly.
sequenceDiagram
participant C as Client
participant A as Node A
participant B as Node B (owner)
C->>A: GET "user:42"
Note over A: Key hashes to Node B
A->>C: MOVED -> Node B (192.168.1.3:7275)
Note over C: Cache: "user:42" -> Node B
C->>B: GET "user:42"
B->>C: OK "alice"
This adds complexity to every client library. The alternative — forward internally and hide the topology from clients — is simpler at the cost of an extra network hop. Redis Cluster proved the MOVED approach works at scale; whether it’s worth it for a project like Mayfly is something I’ll find out.
Redis Cluster sends MOVED as a RESP error string:
-MOVED 3999 127.0.0.1:6381\r\nSlot number and target address embedded in human-readable text. Clients parse the string to extract the redirect target. Mayfly’s binary equivalent packs the same information into a fixed-size response: status byte 0x10 (MOVED), followed by a 4-byte IP and 2-byte port in the payload. No string parsing, no ambiguity about address format. Redis’s approach is easier to debug with redis-cli; the binary approach is easier to parse in client libraries.
Request ID: Enabling Multiplexing
The request ID is a 4-byte value assigned by the client and echoed verbatim in the server’s response. It answers a simple question: “Which request does this response belong to?”
Without a request ID, the protocol is strictly sequential — send a request, wait for the response, send the next request. With one, the client can pipeline multiple requests without waiting:
sequenceDiagram
participant C as Client
participant S as Server
C->>S: [ReqID=1] GET "user:1"
C->>S: [ReqID=2] GET "user:2"
C->>S: [ReqID=3] SET "session:abc"
S->>C: [ReqID=2] OK "alice"
S->>C: [ReqID=3] OK
S->>C: [ReqID=1] OK "bob"
Responses arrive out of order. Request 2 was a local cache hit, request 3 was a fast write, and request 1 required a disk read. The request ID lets the client match each response to its original request regardless of arrival order.
Four bytes gives around 4.3 billion IDs before wrapping. At 10,000 requests/second, that’s nearly 5 days. Wrapping is fine as long as no two in-flight requests share the same ID. A simple monotonically incrementing counter works.
Payload Length: TCP’s Missing Message Boundaries
TCP has no message boundaries — your protocol must create them.
The payload length field (4 bytes) tells the parser exactly how many more bytes to read after the header. One complete message.
Length-prefix framing. Standard for binary protocols. The alternative is delimiter-based framing (like HTTP’s \r\n\r\n or Redis RESP’s \r\n), which requires scanning every byte for the delimiter and can’t contain the delimiter character in the payload without escaping.
flowchart LR
subgraph LP["Length-prefix framing"]
direction LR
L1["len: 15"] --> L2["payload (15 bytes)"]
end
subgraph DL["Delimiter framing"]
direction LR
D1["payload (??? bytes)"] --> D2["\\r\\n"]
end
style L1 fill:#2d5016,stroke:#4a8c2a,color:#fff
style L2 fill:#1a1a2e,stroke:#4a4a6a,color:#fff
style D1 fill:#1a1a2e,stroke:#4a4a6a,color:#fff
style D2 fill:#4a1942,stroke:#8c2a7a,color:#fff
With length-prefix, the reader knows exactly when to stop. Read len bytes and you’re done. With delimiters, you must scan every byte looking for the terminator. Length-prefix wins for binary protocols because the payload can contain arbitrary bytes, including the delimiter itself. Delimiter framing works well for text protocols (RESP, SMTP) where the payload is constrained.
The same SET operation in both styles:
# Redis RESP (delimiter-framed, text)*3\r\n # Array of 3 elements$3\r\n # Bulk string, 3 bytesSET\r\n # Command$3\r\n # Bulk string, 3 bytesfoo\r\n # Key$3\r\n # Bulk string, 3 bytesbar\r\n # Value# Mayfly (length-prefix framed, binary)CA FE 01 01 # Magic + Version + SET command00 00 00 01 # Request ID: 100 00 00 09 # Payload: 9 bytes00 03 66 6F # Key length: 3, Key: "foo"6F 00 00 00 # Value length: 303 62 61 72 # Value: "bar"RESP is 37 bytes of ASCII. The binary version is 21 bytes. At 100k ops/second, that’s 1.5 MB/s saved on framing alone. RESP’s advantage: you can debug it with nc and your eyes.
Byte Order: The Bug You Won’t Find in Unit Tests
Every multi-byte integer in your protocol must be serialized in a defined byte order. If you don’t specify this explicitly in your spec, you’ll discover the bug when a little-endian client (x86, most of the world) talks to a big-endian system, or when someone reads your hex dumps and the numbers look backward.
Use big-endian (network byte order). Always. It’s the convention for network protocols since the 1970s, and it’s what htonl/ntohl convert to/from.
State this explicitly in your spec: “All multi-byte integers are transmitted in network byte order (big-endian).” Then make sure every serialization path respects it:
// C — network byte order conversion#include <arpa/inet.h>
uint32_t payload_len = 1024;uint32_t wire_len = htonl(payload_len);memcpy(buf + 8, &wire_len, sizeof(wire_len));
// Reading backuint32_t net_len;memcpy(&net_len, buf + 8, sizeof(net_len));uint32_t host_len = ntohl(net_len);// Rust — explicit big-endian byteslet payload_len: u32 = 1024;buf[8..12].copy_from_slice(&payload_len.to_be_bytes());
// Reading backlet payload_len = u32::from_be_bytes(buf[8..12].try_into().unwrap());// Go — binary.BigEndianbinary.BigEndian.PutUint32(buf[8:12], 1024)
// Reading backpayloadLen := binary.BigEndian.Uint32(buf[8:12])A related mistake: using native struct serialization. memcpy(&header, buf, sizeof(header)) is tempting in C, but it breaks across architectures with different alignment or endianness. Serialize field by field.
Reading from TCP: The #1 Implementation Bug
This trips up nearly every first-time protocol implementor.
TCP’s read() can return any number of bytes from 1 to the requested amount. If you ask to read 12 bytes (your header), you might get 4 on the first call and 8 on the second. This is normal TCP behavior. The stream has no obligation to deliver data in the chunks you sent it.
sequenceDiagram
participant Sender
participant TCP Stream
participant read()
Sender->>TCP Stream: 12-byte header (CA FE 01 00 ...)
Note over TCP Stream: TCP buffers and<br/>fragments freely
TCP Stream->>read(): Call 1: 4 bytes (CA FE 01 00)
Note over read(): Not a full header!
TCP Stream->>read(): Call 2: 8 bytes (00 00 00 01 00 00 00 0C)
Note over read(): Now you have all 12
The fix is io.ReadFull in Go, read_exact in Rust, or a loop-until-complete in C. Never use a bare read() and assume you got the full header:
func readMessage(conn net.Conn) (*Message, error) { var hdr [12]byte if _, err := io.ReadFull(conn, hdr[:]); err != nil { return nil, fmt.Errorf("read header: %w", err) }
magic := binary.BigEndian.Uint16(hdr[0:2]) if magic != 0xCAFE { return nil, fmt.Errorf("bad magic: 0x%04X", magic) }
payloadLen := binary.BigEndian.Uint32(hdr[8:12]) if payloadLen > MaxPayloadSize { return nil, fmt.Errorf("payload too large: %d bytes", payloadLen) }
payload := make([]byte, payloadLen) if _, err := io.ReadFull(conn, payload); err != nil { return nil, fmt.Errorf("read payload: %w", err) }
return &Message{ Version: hdr[2], Command: hdr[3], RequestID: binary.BigEndian.Uint32(hdr[4:8]), Payload: payload, }, nil}The payloadLen > MaxPayloadSize check matters. Validate the payload length before allocating. A malicious or buggy client claiming a 2 GB payload shouldn’t cause an out-of-memory crash. Set per-command maximums. A GET request payload can’t exceed 258 bytes (2-byte key length + 256-byte max key), so reject anything larger.
Payload Encoding: Structuring the Body
The header tells you what the message is. The payload contains the data. What matters is how you encode variable-length fields inside it.
Length-Prefixed Fields
The standard approach. Every variable-length value is preceded by its byte length:
# SET "foo" = "bar" with 60s TTL:
00 03 # Key length: 3 66 6F 6F # Key: "foo" 00 00 00 03 # Value length: 3 62 61 72 # Value: "bar" 00 00 00 3C # TTL: 60 secondsNotice the asymmetric field widths: 2 bytes for key length, 4 bytes for value length. In Mayfly, the max key size is 256 bytes and the max value is 64 KB, so these widths match the constraints. Match the field width to the maximum size of the data it describes. Don’t waste bytes, but don’t artificially constrain future headroom either.
Strings are length-prefixed, never null-terminated. This is a hard rule. A missing null terminator causes the parser to read past the buffer. That’s a security vulnerability. Length-prefixed strings have unambiguous boundaries and can contain null bytes in the data.
Repeated Structures
When a response contains multiple items (a list of keys, a set of hash fields), use count-prefixed arrays:
# Response with 2 keys:
00 00 00 02 # Count: 2 00 03 # Key 1 length: 3 66 6F 6F # Key 1: "foo" 00 03 # Key 2 length: 3 62 61 72 # Key 2: "bar"The count tells the parser the iteration count. Each element is self-describing via its own length prefix. No sentinel values, no “read until you hit a zero” — those patterns are fragile and make partial parsing impossible.
Tag-Length-Value (TLV) for Extensibility
What happens when you need to add an optional field to a command in v2? If your payload is a flat sequence of fields, adding one in the middle breaks every existing parser.
TLV solves this:
Each field: Tag: 2 bytes (field identifier) Length: 2 bytes (length of value) Value: [Length] bytesUnknown tags are skippable. The parser reads the tag, doesn’t recognize it, reads the length, skips that many bytes, and moves on. New fields can be added without breaking old clients.
flowchart LR
subgraph "v1 parser reading a v2 message"
direction LR
T1["tag: 0x01<br />(known)"] --> L1["len: 4"] --> V1["value<br />4 bytes<br />✓ parse"]
V1 --> T2["tag: 0x99<br />(unknown!)"] --> L2["len: 8"] --> V2["value<br />8 bytes<br />⏭ skip"]
end
style T1 fill:#2d5016,stroke:#4a8c2a,color:#fff
style L1 fill:#2d5016,stroke:#4a8c2a,color:#fff
style V1 fill:#2d5016,stroke:#4a8c2a,color:#fff
style T2 fill:#4a1942,stroke:#8c2a7a,color:#fff
style L2 fill:#4a1942,stroke:#8c2a7a,color:#fff
style V2 fill:#4a1942,stroke:#8c2a7a,color:#fff
The tradeoff is 4 bytes of overhead per field. For payloads with 2-3 fields, that’s negligible. For payloads with 10+ fields, consider Protocol Buffers or FlatBuffers instead of hand-rolling TLV.
When to Reach for Protobuf
If your payloads are deeply nested, your schema evolves frequently, or cross-language support matters more than raw performance, use protobuf for the message body and keep your fixed binary header for framing. Apache Pulsar does exactly this. The header stays fast and fixed-size for routing and multiplexing; the body gets protobuf’s type system and backward compatibility.
For flat key-value payloads with stable schemas, like a database protocol’s SET and GET, hand-rolled binary is fine and avoids the protobuf dependency.
Connection Lifecycle: What Happens After Connect
Connect, authenticate, operate, disconnect. Ambiguity in any phase means bugs that only surface under specific timing or failure conditions.
sequenceDiagram
participant C as Client
participant S as Server
Note over C,S: TCP handshake (kernel)
C->>S: Magic + Version
S-->>S: Validate
C->>S: AUTH (token)
alt Auth success
S->>C: OK
C->>S: SET / GET / ...
S->>C: OK / value / ...
C->>S: PING
S->>C: OK
C->>S: QUIT
S->>C: OK
Note over C,S: Both sides close
else Auth failure
S->>C: AUTH_FAILED
Note over S: Server closes connection
end
Authentication: First or Not at All
If your protocol supports authentication, AUTH must be the first command after the TCP handshake. Any command before successful authentication gets AUTH_REQUIRED and is not executed. On auth failure, respond AUTH_FAILED and close the connection. Don’t let unauthenticated clients probe the server’s command space or discover what commands exist.
The AUTH payload is a length-prefixed token:
CA FE 01 00 00000001 0000000C # Header: AUTH, ReqID=1, 12 bytes payload000A # Token length: 107365637265747...6E # Token: "secrettoken"Postgres’s auth error responses include a reason code (wrong password, unknown user, SSL required). This improves the debugging experience without leaking exploitable information. Be deliberate about what you expose.
What Postgres actually sends on auth failure:
45 # 'E' — ErrorResponse00 00 00 57 # Length: 87 bytes53 # 'S' — Severity field45 52 52 4F 52 00 # "ERROR\0"43 # 'C' — SQLSTATE code32 38 50 30 31 00 # "28P01\0" (invalid_password)4D # 'M' — Human-readable message70 61 73 73 77 6F # "password authentication72 64 20 61 75 74 # failed for user68 65 6E 74 69 63 # \"postgres\"\0"...00 # TerminatorSingle-byte field codes (S, C, M, D for detail, H for hint) followed by null-terminated strings. The client branches on the SQLSTATE code (28P01 = wrong password, 28000 = invalid authorization) without parsing the human message. Structured enough to be useful, terse enough to fit in a single response.
TLS handles encryption and channel verification at the transport layer. Your application protocol just handles session authentication.
Keepalives: Detecting Dead Peers
Without application-level keepalives, a crashed or firewalled peer goes undetected until the next send attempt, which could be minutes or hours later. TCP keepalives exist but are configured at the OS level and typically have long default intervals (2 hours on Linux).
A PING/PONG exchange at the application level (every 30 seconds is reasonable) gives you sub-minute failure detection. It also gives load balancers and firewalls traffic to keep the connection alive through NAT tables and idle timeouts.
Graceful Shutdown: QUIT vs Crash
QUIT lets the server distinguish an intentional disconnect from a crash. In a single-node system, this is a minor convenience. In a distributed system, it matters: a QUIT triggers immediate rebalancing of the departing node’s data, while a dropped connection requires waiting out a suspicion timeout before declaring the node dead.
When One Protocol Isn’t Enough
If your system has any distributed component — replication, sharding, gossip, consensus — you’ll eventually discover that the client protocol can’t serve double duty for internal traffic. The constraints diverge too much.
A client protocol optimizes for simplicity. Small header, straightforward request-response, easy to implement in any language. The client doesn’t need to know about hash rings, replication factors, or node UUIDs.
Node-to-node communication needs entirely different metadata. Forwarding a client request to the correct owner requires the original request ID, command, consistency level, and a hop count to prevent forwarding loops. Replication carries causality timestamps the client never sees. Gossip messages carry membership state. None of this belongs in the client protocol.
In Mayfly, I ended up with two separate protocols. Possibly overkill for what’s still an experiment, but the separation has made debugging significantly easier:
flowchart LR
C[Clients] -->|":7275"| CP
N[Other Nodes] -->|":8275"| KP
subgraph Node["Mayfly Node"]
CP["Client Protocol<br />0xCAFE · 12B header<br />SET, GET, DEL, PING, AUTH ..."]
KP["Cluster Protocol<br />0xBEE5 · 24B header<br />FORWARD, REPLICATE, SYNC ..."]
end
style CP fill:#2d5016,stroke:#4a8c2a,color:#fff
style KP fill:#4a1942,stroke:#8c2a7a,color:#fff
style C fill:#1a1a2e,stroke:#4a4a6a,color:#fff
style N fill:#1a1a2e,stroke:#4a4a6a,color:#fff
Separate ports and separate magic numbers. A misrouted message fails immediately — either at the port level (wrong listener) or at byte zero (wrong magic). No ambiguous parsing.
The cluster header is larger because it carries the sender’s UUID in every message. The receiver never needs to correlate messages with connection state — connections can die and re-establish without identity ambiguity. 16 bytes per message for that guarantee felt worth it at Mayfly’s expected message rates.
Distributed Protocol Concerns
Once you have a cluster protocol, new questions emerge. Distributed systems theory rather than byte layout, and harder. What follows covers the protocol-surface implications — what your wire format needs to carry — not how to implement these algorithms. The papers in the Further Reading section go deep on the theory.
Causality: Who Wrote Last?
Replication creates a conflict resolution problem. Two nodes accept writes to the same key concurrently — which one wins? Wall-clock time is unreliable across machines (clock skew, NTP jumps), so you need a logical or hybrid clock.
Hybrid Logical Clocks (HLC) are a common approach for last-write-wins semantics, and what Mayfly attempts to use (though I won’t pretend the implementation is battle-tested). A typical HLC structure:
block-beta
columns 3
A["Wall Clock<br />8 bytes<br />2026-03-01 12:34:56"]:1
B["Counter<br />4 bytes<br />00007"]:1
C["Node UUID<br />16 bytes<br />a1b2c3d4-..."]:1
style A fill:#2d5016,stroke:#4a8c2a,color:#fff
style B fill:#1a1a2e,stroke:#4a4a6a,color:#fff
style C fill:#4a1942,stroke:#8c2a7a,color:#fff
28 bytes total. Comparison order: wall time, then counter, then UUID as a deterministic tiebreaker.
28 bytes per replicated write. Negligible for kilobyte values; significant for counter increments.
Request Forwarding and Hop Counts
In a sharded system, a node might receive a request for a key it doesn’t own. It can either redirect the client (MOVED) or forward the request internally.
sequenceDiagram
participant C as Client
participant A as Node A
participant B as Node B (owner)
C->>A: SET "foo" (ReqID=5)
Note over A: Key hashes to Node B
A->>B: FORWARD (ReqID=5, hop=1)
B->>B: Apply write
B->>A: OK
A->>C: OK (ReqID=5)
Without a hop count, a topology misconfiguration (Node A thinks Node B owns the key, Node B thinks Node A owns it) creates an infinite forwarding loop. A max hop of 1 or 2 means the request fails fast with TOPOLOGY_CHANGED instead of bouncing forever.
Gossip: Membership Without a Coordinator
Without an external coordinator (etcd, ZooKeeper), nodes need to discover each other, detect failures, and agree on membership. SWIM gossip is the standard approach: periodic PING/PONG exchanges, indirect probes (PING_REQ) when a direct PING fails, and piggybacked membership state on every message.
sequenceDiagram
participant A as Node A
participant B as Node B
participant C as Node C
A->>B: PING
Note over A: Timeout — no PONG
A->>C: PING_REQ (probe B)
C->>B: PING
B->>C: PONG
C->>A: ACK (B alive)
These messages belong on the cluster protocol, never the client protocol. Keep gossip messages small. The PING hot path should be just the cluster header plus a membership hash. Full membership state gets exchanged less frequently.
Anti-Entropy: Catching What Gossip Misses
Gossip handles failure detection and membership, not data consistency. Anti-entropy handles that: periodic comparison of data state between replicas.
Merkle trees are the standard mechanism. Each node builds a hash tree over its key space. Nodes exchange root hashes, and on mismatch, walk the tree to find divergent keys:
flowchart TD
subgraph "Replica A"
RA["H_root"] --> RA1["H_ab"] & RA2["H_cd"]
RA1 --> A1["a"] & A2["b"]
RA2 --> A3["c"] & A4["d"]
end
subgraph "Replica B"
RB["H_root'"] --> RB1["H_ab"] & RB2["H_cd'"]
RB1 --> B1["a"] & B2["b"]
RB2 --> B3["c'"] & B4["d"]
end
RA -. "roots differ!" .- RB
RA2 -. "narrow down" .- RB2
A3 -. "diverged!" .- B3
style RA fill:#4a1942,stroke:#8c2a7a,color:#fff
style RB fill:#4a1942,stroke:#8c2a7a,color:#fff
style RA2 fill:#4a1942,stroke:#8c2a7a,color:#fff
style RB2 fill:#4a1942,stroke:#8c2a7a,color:#fff
style A3 fill:#ff5555,stroke:#ff5555,color:#fff
style B3 fill:#ff5555,stroke:#ff5555,color:#fff
style RA1 fill:#2d5016,stroke:#4a8c2a,color:#fff
style RB1 fill:#2d5016,stroke:#4a8c2a,color:#fff
style A1 fill:#2d5016,stroke:#4a8c2a,color:#fff
style A2 fill:#2d5016,stroke:#4a8c2a,color:#fff
style A4 fill:#2d5016,stroke:#4a8c2a,color:#fff
style B1 fill:#2d5016,stroke:#4a8c2a,color:#fff
style B2 fill:#2d5016,stroke:#4a8c2a,color:#fff
style B4 fill:#2d5016,stroke:#4a8c2a,color:#fff
The protocol needs a sync request (key range + local Merkle root) and a streamable sync response (differing key-value pairs with their HLC timestamps).
sequenceDiagram
participant A as Replica A
participant B as Replica B
A->>B: SYNC_REQ (range + merkle root)
Note over B: Compare root hashes
alt Roots match
B->>A: SYNC_OK
else Roots differ
Note over A,B: Walk tree to find divergent keys
B->>A: SYNC_DIFF (key + value + HLC)
B->>A: SYNC_DIFF (key + value + HLC)
B->>A: SYNC_END
end
The streamable part matters. A large partition might contain thousands of divergent keys. The response needs to be a sequence of individual key-value messages, not one giant payload.
Backward-Compatible Extensions
Adding features without breaking existing clients is hard.
A problem I ran into with Mayfly (and one that any protocol with multiple deployment modes will hit): adding per-request consistency levels (ONE, QUORUM, ALL) for cluster mode. Standalone clients — the ones that existed first — know nothing about consistency. They send 12-byte headers. Cluster-aware clients need to specify a consistency level. How do you add it without breaking the existing clients?
One approach: an optional 13th byte appended to the header:
block-beta
columns 6
A["Standard header — 12 bytes"]:6
M1["CAFE"] V1["01"] C1["cmd"] R1["reqID"] P1["payloadLen"] space
space:6
B["With consistency extension — 13 bytes"]:6
M2["CAFE"] V2["02"] C2["cmd"] R2["reqID"] P2["payloadLen"] CL["consistency"]
style A fill:none,stroke:none,color:#8be9fd
style B fill:none,stroke:none,color:#8be9fd
style CL fill:#2d5016,stroke:#4a8c2a,color:#fff
style M1 fill:#1a1a2e,stroke:#4a4a6a,color:#fff
style V1 fill:#1a1a2e,stroke:#4a4a6a,color:#fff
style C1 fill:#1a1a2e,stroke:#4a4a6a,color:#fff
style R1 fill:#1a1a2e,stroke:#4a4a6a,color:#fff
style P1 fill:#1a1a2e,stroke:#4a4a6a,color:#fff
style M2 fill:#1a1a2e,stroke:#4a4a6a,color:#fff
style V2 fill:#1a1a2e,stroke:#4a4a6a,color:#fff
style C2 fill:#1a1a2e,stroke:#4a4a6a,color:#fff
style R2 fill:#1a1a2e,stroke:#4a4a6a,color:#fff
style P2 fill:#1a1a2e,stroke:#4a4a6a,color:#fff
The version byte does the work here. A v1 (0x01) header is always 12 bytes. A v2 (0x02) header is 13, and the server reads the extra byte as the consistency level. If the consistency byte is absent (v1), default to QUORUM. A standalone server that only speaks v1 never sees the extra byte at all.
New features should be additive, with sensible defaults for unaware participants. MQTT v5 does this well. Each property has a type ID, length, and value. Unrecognized properties are skipped by the parser.
A CONNECT packet with a 30-minute session expiry:
# MQTT v5 Properties section05 # Properties length: 5 bytes11 # Property ID: 0x11 (Session Expiry Interval)00 00 07 08 # Value: 1800 seconds (big-endian uint32)Property ID 0x11 is a 4-byte integer. Property ID 0x03 (Content Type) is a UTF-8 string. Property ID 0x26 (User Property) is a key-value string pair that can repeat. A v5 parser that doesn’t recognize a property reads the ID, looks up the wire type from the spec, reads that many bytes, and skips. An older parser hits the properties length field, skips the whole block, and carries on.
Persistence: The Third Protocol
If your system supports durability, there’s effectively a third protocol. One that targets disk instead of the network. A write-ahead log (WAL): every mutation is serialized to an append-only file before the in-memory apply.
The on-disk format shares structural patterns with the wire protocol (length-prefixed fields, big-endian integers, operation codes) but differs in what metadata it needs. The wire protocol needs a request ID and magic bytes for connection management. The disk format needs a CRC for crash recovery and a timestamp for replay ordering:
WAL Entry: CRC-32: 4 bytes (integrity check) Timestamp: 8 bytes (ms since epoch) Operation: 1 byte (SET, DEL, etc.) Key Length: 2 bytes Key: N bytes Value Length: 4 bytes Value: N bytes TTL: 4 bytesThe CRC-32 is how you handle crash recovery. A mid-write crash leaves a partially written entry. On startup, replay entries sequentially, validating each CRC. A bad CRC means a torn entry — truncate the log at that point and resume.
block-beta
columns 5
A["Entry 1<br />CRC ✓"] B["Entry 2<br />CRC ✓"] C["Entry 3<br />CRC ✓"] D["Entry 4<br />CRC ✓"] E["torn entry<br />CRC ✗<br />← truncate here"]
style A fill:#2d5016,stroke:#4a8c2a,color:#fff
style B fill:#2d5016,stroke:#4a8c2a,color:#fff
style C fill:#2d5016,stroke:#4a8c2a,color:#fff
style D fill:#2d5016,stroke:#4a8c2a,color:#fff
style E fill:#ff5555,stroke:#ff5555,color:#fff
Data after the torn entry is lost, but the log is consistent. You might lose the last few milliseconds of writes. The log will always be recoverable.
Give the WAL file its own header with a magic number and version byte, just like the wire protocol. When you change the entry format in v2, the version byte tells the replay logic which parser to use.
Build Debugging Tools Before You Need Them
You’ll spend more time debugging the protocol than designing it. Build the tooling alongside it, not after the first production incident.
Hex Dump Sender
A command-line tool that parses annotated hex files and sends raw bytes over TCP:
CA FE # Magic01 # Version00 # Command: AUTH00 00 00 01 # Request ID: 100 00 00 0C # Payload length: 12 bytes00 0A # Token length: 1073 65 63 72 65 # Token: "secrettoken"74 74 6F 6B 656EHand-crafting packets in a text editor and firing them at the server catches framing bugs, off-by-one length errors, and endianness issues faster than writing client code. You can test the server before the client library even exists.
Wire Logger
A server mode that decodes and logs every message:
<-- RECV [12+12=24 bytes] Magic=0xCAFE Ver=1 Cmd=0x00(AUTH) ReqID=1 Len=12 Payload: 00 0A 73 65 63 72 65 74 74 6F 6B 65 6E
--> SEND [12+0=12 bytes] Magic=0xCAFE Ver=1 Status=0x01(OK) ReqID=1 Len=0The binary equivalent of HTTP access logs. When something goes wrong, you’ll know exactly what bytes crossed the wire.
Fuzzing
Throw random bytes at the parser. Go’s built-in fuzzing (since 1.18) is particularly effective here. Common findings: buffer over-reads from untrusted length fields, integer overflows in offset calculations, and OOM from crafted payload lengths. Every one of these is a bug you want to find before deployment.
Things That Will Bite You
Not using io.ReadFull (or equivalent). Works on localhost. Breaks in production.
Trusting client-provided lengths. One malicious packet claiming a 2 GB payload OOMs your server.
No version field. Heuristic version detection breaks. Already covered, still the #1 regret in protocol design.
Not setting TCP_NODELAY. Nagle’s algorithm batches small writes, adding up to 40ms latency per message on low-throughput connections. For a request-response protocol where every message is a complete frame, Nagle does nothing useful and kills perceived performance.
Testing only on localhost. Partial reads, packet reordering, and MTU fragmentation don’t happen over loopback. Your protocol works on your machine and breaks over a real network. Test across machines early, or at minimum use tc to simulate latency and packet loss.
Flat command numbering. Sequential assignment (0x00, 0x01, 0x02, …) works until you have 30+ commands and hex dumps become inscrutable. Group by nibble from the start.
Reusing command byte semantics across versions. If v1’s 0x01 means SET, v2 cannot repurpose 0x01 to mean something else. This creates bugs that only surface when a v1 client talks to a v2 server — exactly the scenario versioning exists to handle.
Sharing a port for multiple protocols. Separate ports mean the OS selects the listener for you. No magic-byte peeking, simpler firewall rules, cleaner separation of concerns.
Further Reading
Protocols worth studying:
- Kafka protocol spec — one of the best-documented binary protocols. Covers primitive types, framing, versioning, and every message format in detail.
- PostgreSQL frontend/backend protocol — excellent on authentication flows, pipelining, and error semantics.
- Redis RESP — a text-based protocol designed for similar workloads to binary ones. Useful as a counterpoint.
- MQTT — worth studying for constrained environments and its property extension system.
- Source RCON Protocol — a minimal binary command protocol. Instructive partly for what it gets wrong (no version field).
For distributed systems foundations: the Dynamo paper, the SWIM paper, and the HLC paper. These are the theoretical underpinnings most distributed key-value stores build on — including Mayfly’s attempt at them. Reading the papers before designing the protocol was, in hindsight, the most valuable thing I did.