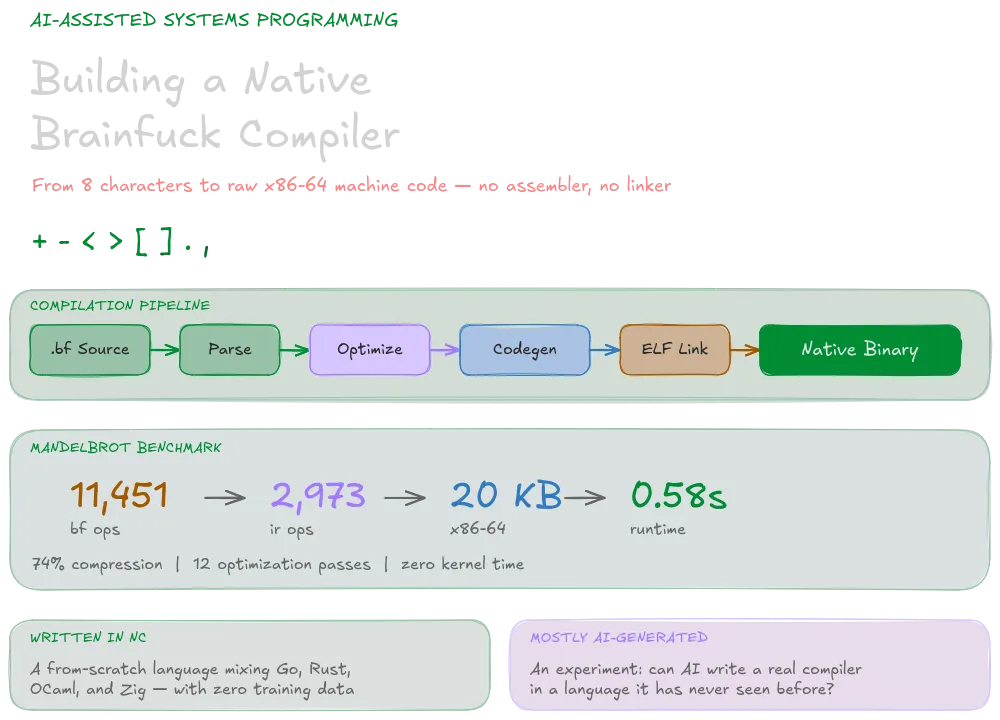
bfcc is a brainfuck compiler that takes .bf/.b/.fck (not really clear on which one is the official) source files and produces native Linux ELF64 binaries.
This results in a Mandelbrot set renderer written in brainfuck compiling to an around 21 KB binary and executing in 0.58 seconds, now, whether that’s considered impressive or not is up to you, but it’s a fun demonstration of how much you can optimize even a language as minimal as brainfuck.
What brainfuck actually is
Brainfuck operates on a tape of 30,000 bytes initialized to zero, with a movable data pointer. The entire language is eight characters:
| Op | Description |
|---|---|
> | Move the data pointer right |
< | Move the data pointer left |
+ | Increment the byte at the data pointer |
- | Decrement the byte at the data pointer |
. | Output the byte at the data pointer |
, | Read one byte of input into the current cell |
[ | Jump past matching ] if current cell is 0 |
] | Jump back to matching [ if current cell != 0 |
Everything else is a comment. People have written some seriously awesome programs in this from fractal renderers to sorting algorithms and self-interpreters all of which I do not have the patience, brains, or sanity to do myself.

The compilation pipeline
The compiler follows a standard multi-stage pipeline. Each stage transforms the program into a progressively lower-level representation until we’re writing raw bytes to disk.
flowchart LR
A["Source"] --> B["Strip & Val"]
B --> C["Parse to IR"]
C --> D["Optimize"]
D --> E["Emit x86-64"]
E --> F["Wrap in ELF64"]
F --> G["Write Binary"]
style A fill:#1a1a2e,stroke:#00ff66,color:#d4f5e0
style B fill:#1a1a2e,stroke:#00cc52,color:#d4f5e0
style C fill:#1a1a2e,stroke:#00cc52,color:#d4f5e0
style D fill:#1a1a2e,stroke:#ffb800,color:#d4f5e0
style E fill:#1a1a2e,stroke:#00e5ff,color:#d4f5e0
style F fill:#1a1a2e,stroke:#ff3c7f,color:#d4f5e0
style G fill:#1a1a2e,stroke:#00ff66,color:#d4f5e0
Let’s walk through each stage.
Stage 1: Stripping and validation
The first pass is simple but important. We scan every byte in the source file and keep only the eight valid brainfuck characters. Everything else, whitespace, comments, stray characters can gets dropped like a hot potato. This is easier than having to do a conversion of the bytes -> chars and then back to bytes later on. We just work with bytes the whole time.
Also should be noted that unlike other languages we don’t need a complex lexer or tokenization step. Brainfuck’s syntax is so minimal that we can parse directly from the raw character stream without an intermediate token representation.
Then we validate bracket matching. Every [ needs a corresponding ]. This is a simple depth counter: increment on [, decrement on ], and if we ever go negative or end with a nonzero depth, the source is malformed.
fn validate_brackets(byte[] src) -> error { mut int depth = 0 for i in src { if src[i] { byte(0x5B) -> { depth = depth + 1 } byte(0x5D) -> { depth = depth - 1 if depth { $:-1 -> { return error("unmatched ']' at position {str(i)}") } _ -> {} } } _ -> {} } } return if depth { 0 -> { none } _ -> { error("{str(depth)} unmatched '['") } }}Catching errors here means we never have to worry about malformed input downstream. The rest of the compiler can assume the program is structurally valid.
Stage 2: Parsing to intermediate representation
This is where things get interesting. Rather than working directly with characters, we parse brainfuck into a typed IR (intermediate representation) with thirteen operation types:
enum Op { MovePtr(int), // pointer delta (collapsed runs) AddVal(int), // cell value delta (collapsed runs) AddAt(int, int), // offset + delta (touch memory at a distance) MulAdd(int, int), // offset + factor (multiply-accumulate) Scan(int), // step direction (search for zero cell) Output, // write current cell OutputAt(int), // write cell at offset Accept, // read into current cell AcceptAt(int), // read into cell at offset LoopStart, // [ LoopEnd, // ] SetZero, // cell = 0 SetAt(int, int), // cell at offset = value}The first optimization happens during parsing itself: run-length encoding. Ten consecutive + characters don’t become ten separate increment operations — they become a single AddVal(10). Same for pointer moves: >>>> becomes MovePtr(4).
We also detect the [-] and [+] idioms immediately. These are the canonical “set cell to zero” patterns, so they become SetZero rather than a loop with a decrement.
Stage 3: The optimization pipeline
This is where most of the performance comes from. The compiler runs twelve optimization passes, each building on the results of the previous ones.
flowchart TD
A["Raw IR Ops"] --> B["Combine Linear Ops"]
B --> C["Balanced Pointer Runs"]
C --> D["Combine Linear Ops"]
D --> E["Multiply Loop Lowering"]
E --> F["Combine Linear Ops"]
F --> G["Scan Loop Lowering"]
G --> H["Schedule Linear Blocks"]
H --> I["Combine Linear Ops"]
I --> J["Fold Set Ops"]
J --> K["Propagate Known Values"]
K --> L["Fold Set Ops"]
L --> M["Combine Linear Ops"]
M --> N["Optimized IR"]
style A fill:#1a1a2e,stroke:#666,color:#d4f5e0
style N fill:#1a1a2e,stroke:#00ff66,color:#d4f5e0
style B fill:#1a1a2e,stroke:#00cc52,color:#d4f5e0
style C fill:#1a1a2e,stroke:#00cc52,color:#d4f5e0
style D fill:#1a1a2e,stroke:#00cc52,color:#d4f5e0
style E fill:#1a1a2e,stroke:#ffb800,color:#d4f5e0
style F fill:#1a1a2e,stroke:#00cc52,color:#d4f5e0
style G fill:#1a1a2e,stroke:#ffb800,color:#d4f5e0
style H fill:#1a1a2e,stroke:#00e5ff,color:#d4f5e0
style I fill:#1a1a2e,stroke:#00cc52,color:#d4f5e0
style J fill:#1a1a2e,stroke:#ff3c7f,color:#d4f5e0
style K fill:#1a1a2e,stroke:#ff3c7f,color:#d4f5e0
style L fill:#1a1a2e,stroke:#ff3c7f,color:#d4f5e0
style M fill:#1a1a2e,stroke:#00cc52,color:#d4f5e0
Combine linear ops
This is the workhorse pass that runs multiple times between other passes. It merges adjacent operations of the same type: consecutive AddVal ops get summed, consecutive MovePtr ops get summed, and consecutive AddAt ops targeting the same offset get summed.
If the net result is zero (you added 3 then subtracted 3), the operation is eliminated entirely. This pass cleans up the artifacts left behind by other transformations.
Balanced pointer runs
A common brainfuck pattern is: move the pointer somewhere, do work, move it back. Something like >>++++<< moves right 2, adds 4, moves left 2. The net pointer displacement is zero.
This pass detects these “balanced runs” and replaces the pointer moves with offset operations. Instead of generating three instructions (move, add, move back), we emit a single AddAt(2, 4) — add 4 to the cell at offset +2 from the current position. No pointer movement needed.
Multiply loop lowering
This is one of the most performance improving optimizations. Consider this brainfuck:
[->+++<]This loop decrements the current cell by 1 and adds 3 to the next cell, repeating until the current cell is zero. It’s multiplying the current cell’s value by 3 and storing the result one cell to the right.
The optimizer detects this pattern by analyzing the loop body:
- Confirm the loop contains only
AddValandAddAtoperations (after balanced pointer run optimization) - Confirm the “source” cell (offset 0) has a net delta of -1 per iteration
- Extract the coefficients for all other cells
The entire loop gets replaced with MulAdd operations followed by SetZero:
// [->+++<] becomes:MulAdd(1, 3) // cell[ptr+1] += cell[ptr] * 3SetZero // cell[ptr] = 0One iteration of the loop body, executed once, replaces what could be hundreds of iterations. For the Mandelbrot program, this eliminates some of the hottest inner loops.
Scan loop lowering
Brainfuck programs often need to search for the next zero cell in a direction. The pattern [>] means “keep moving right until you hit a zero.” This gets lowered to a Scan(1) operation, which we can compile to a very tight compare-and-branch loop in machine code.
Linear block scheduling
After the previous passes, we often have sequences like:
MovePtr(3), AddVal(1), MovePtr(-3)The scheduling pass looks at “linear blocks” — sequences of operations between loop boundaries — and eliminates redundant pointer movement. It tracks a virtual pointer offset and converts operations to their offset equivalents:
// Before scheduling:MovePtr(3), AddVal(1), MovePtr(-3), AddVal(5)
// After scheduling:AddAt(3, 1), AddVal(5)// (net pointer movement was zero, so no MovePtr emitted)Value propagation
The final major pass tracks what we know about cell values. If we just executed SetZero, we know the current cell is 0. If the next operation is a loop [...], we can skip the entire loop because we know the condition is false.
This pass also folds sequences like SetZero followed by AddVal(65) into SetAt(0, 65) — set the cell directly to 65 without clearing it first.
The numbers
For the Mandelbrot renderer, the optimization pipeline takes 11,451 raw brainfuck operations down to 2,973 IR operations. That’s a 74% reduction.
| Metric | Count |
|---|---|
| Pointer moves | 819 |
| Value operations | 902 |
| Multiply-accumulates | 4 |
| Scan operations | 2 |
| I/O operations | 3 |
| Cell clears | 97 |
| Cell sets | 28 |
| Loops | 559 |
Stage 4: x86-64 code generation
This is where the compiler earns its name. We don’t generate assembly text to pass through nasm or gas. Rather we emit raw x86-64 machine code bytes directly into a buffer.
Register allocation
The register layout is fixed — brainfuck is simple enough that we don’t need a register allocator:
flowchart LR
subgraph Registers
direction TB
R12["R12 -- tape pointer"]
R13["R13 -- output buffer base"]
R15["R15 -- output write cursor"]
EBX["EBX -- output byte count"]
R10["R10 -- input buffer base"]
R14["R14 -- input read cursor"]
R8D["R8D -- input bytes remaining"]
end
style Registers fill:#0a0f1c,stroke:#00e5ff,color:#d4f5e0
style R12 fill:#1a1a2e,stroke:#00ff66,color:#00ff66
style R13 fill:#1a1a2e,stroke:#ffb800,color:#ffb800
style R15 fill:#1a1a2e,stroke:#ffb800,color:#ffb800
style EBX fill:#1a1a2e,stroke:#ffb800,color:#ffb800
style R10 fill:#1a1a2e,stroke:#00e5ff,color:#00e5ff
style R14 fill:#1a1a2e,stroke:#00e5ff,color:#00e5ff
style R8D fill:#1a1a2e,stroke:#00e5ff,color:#00e5ff
R12 is the data pointer — the heart of the brainfuck machine. All cell accesses go through R12 with various addressing modes. The output side uses a 4 KB write buffer that flushes via write(2) syscall when full. Input is similarly buffered with read(2).
The CodeBuf emitter
The core of codegen is a CodeBuf struct that manages a byte buffer with a write cursor. It has methods for emitting individual bytes, little-endian 32/64-bit values, and higher-level helpers for common instruction patterns.
Here’s what emitting an AddVal looks like under the hood. For AddVal(1), we want the x86-64 instruction inc byte [r12]:
// inc byte [r12] --> 41 FE 04 24self.b(0x41) // REX.B prefix (r12 is an extended register)self.b(0xFE) // INC r/m8 opcodeself.b(0x04) // ModR/M: mod=00, reg=000 (/0), r/m=100 (SIB follows)self.b(0x24) // SIB: scale=00, index=100 (none), base=100 (r12)For AddVal(-1), we emit dec byte [r12] which differs only in the ModR/M reg field. For arbitrary deltas, we use add byte [r12], imm8 or sub byte [r12], imm8.
The emitter also handles offset addressing. For AddAt(5, 3) (add 3 to the cell 5 positions ahead), the encoding changes based on offset size:
- Offset fits in a signed byte (-128 to 127): Use the
[r12 + disp8]addressing mode. Compact, 5 bytes total. - Larger offsets: Use
[r12 + disp32]addressing mode. 8 bytes total.
This encoding flexibility means most operations in real brainfuck programs use the compact form, keeping code size down.
Loop compilation
Loops are compiled with a forward/backward jump pair:
sequenceDiagram
participant Code as Machine Code Buffer
Note over Code: Encounter LoopStart [
Code->>Code: Emit CMP byte [r12], 0
Code->>Code: Save current position to stack
Code->>Code: Emit JZ with placeholder offset (6 bytes)
Note over Code: ... emit loop body ...
Note over Code: Encounter LoopEnd ]
Code->>Code: Emit JMP back to the CMP instruction
Code->>Code: Pop saved position from stack
Code->>Code: Patch the JZ offset to point here
The key detail is jump encoding optimization. Backward jumps (from ] to [) might fit in a 2-byte short jump (JNZ rel8) if the loop body is small enough (offset fits in a signed byte). Otherwise we fall back to the 6-byte near jump (JNZ rel32). The same applies to the unconditional backward jump. This saves code space in tight inner loops.
Multiply-accumulate codegen
MulAdd(offset, factor) compiles to a compact sequence:
movzx eax, byte [r12] // zero-extend current cell into EAXimul eax, eax, factor // multiply by the factoradd byte [r12+offset], al // add low byte to target cellFor the special cases of factor=1 and factor=-1, we skip the IMUL entirely and emit a direct ADD or SUB. This is a common case when brainfuck copies a cell’s value to a neighbor.
Stage 5: ELF64 linking
The final stage wraps our machine code in a minimal ELF64 binary. We construct the binary ourselves, byte by byte.
Memory layout
block-beta
columns 1
block:code
columns 3
code_title["Code Segment (LOAD, R+X)"]:3
ehdr["ELF Header\n64 bytes"]
phdr["2 PHDRs\n112 bytes"]
mc["Machine Code\nN bytes"]
end
space
block:bss
columns 3
bss_title["BSS Segment (LOAD, R+W)"]:3
tape["Tape\n30,000 bytes"]
obuf["Output Buffer\n4,096 bytes"]
ibuf["Input Buffer\n4,096 bytes"]
end
style code fill:#0d1f15,stroke:#00e5ff,color:#d4f5e0
style bss fill:#1a1a0d,stroke:#ffb800,color:#d4f5e0
style code_title fill:transparent,stroke:transparent,color:#d4f5e0
style bss_title fill:transparent,stroke:transparent,color:#d4f5e0
style ehdr fill:#1a1a2e,stroke:#00e5ff,color:#d4f5e0
style phdr fill:#1a1a2e,stroke:#00e5ff,color:#d4f5e0
style mc fill:#1a1a2e,stroke:#00e5ff,color:#d4f5e0
style tape fill:#1a1a2e,stroke:#ffb800,color:#d4f5e0
style obuf fill:#1a1a2e,stroke:#ffb800,color:#d4f5e0
style ibuf fill:#1a1a2e,stroke:#ffb800,color:#d4f5e0
The binary has exactly two program headers (segments):
-
Code segment at
0x400000(read + execute): Contains the ELF header, program headers, and machine code. Thep_fileszequals the total file size, andp_memszmatches. The entry point is0x400000 + 176(right after the headers). -
BSS segment at
0x800000(read + write): Contains the tape, output buffer, and input buffer. Thep_fileszis 0 (no file backing), andp_memszis 38,192 bytes. The kernel zeros this memory at load time.
We skip section headers entirely. The Linux kernel doesn’t need them to execute a binary — it only reads program headers. This keeps our overhead at exactly 176 bytes (64-byte ELF header + 2 x 56-byte program headers).
Building the ELF header
The ELF header is built with helper functions that emit little-endian values:
fn build_elf_header(int entry_vaddr, int phdr_count) -> byte[] { mut byte[] h = [] // Magic: 0x7F 'E' 'L' 'F' h = h <> [byte(0x7F), byte(0x45), byte(0x4C), byte(0x46)] // Class: 64-bit, Data: little-endian, Version: current, OS/ABI: SYSV h = h <> [byte(2), byte(1), byte(1), byte(0), ...] // Type: ET_EXEC (executable) h = h <> le16(2) // Machine: EM_X86_64 h = h <> le16(0x3E) // Entry point virtual address h = h <> le64(entry_vaddr) // Program header table offset (immediately after ELF header) h = h <> le64(64) // ... remaining fields return h}Putting it all together
Here’s what happens when we compile the Mandelbrot brainfuck program:
$ ./bfcc ./examples/mandelbrot.b -o mandelbrot.out[parse] 11,451 bf ops from 'mandelbrot.b' (11,669 bytes)[optimize] 2,973 ir ops (compressed 8,478 | 97 clear, 28 set) 819 ptr, 902 val, 4 mul, 2 scan, 3 i/o, 559 loops[codegen] 20,632 bytes x86-64[link] 20,808 bytes ELF64[done] mandelbrot.out 11,451 bf -> 2,973 ir -> 20,632 bytes machine code
$ /usr/bin/time -f '%e %U %S %M' ./mandelbrot.out0.58 0.57 0.00 476The full pipeline from source to binary: 11,451 brainfuck ops become 2,973 IR ops become 20,632 bytes of x86-64 machine code wrapped in a 20,808-byte ELF64 binary. Execution time for the Mandelbrot renderer: 0.58 seconds, using 476 KB of peak memory and spending pretty much zero time in kernel space.
Of course, further optimizations are possible; better loop scheduling, more aggressive value tracking, SIMD codegen for certain patterns; but this is a solid cool project.
View the source code on GitHub