This article is more so a test to see how well LaTeX and citations render. Which personally I think turned out pretty clean looking, so hopefully in the future I can write some more in-depth subjects covering compiler optimizations and some of the math that works behind them.
This is one of the most famous functions in game development history:
float Q_rsqrt(float number){ long i; float x2, y; const float threehalfs = 1.5F;
x2 = number * 0.5F; y = number; i = * ( long * ) &y; // evil floating point bit level hacking i = 0x5f3759df - ( i >> 1 ); // what the fuck? y = * ( float * ) &i; y = y * ( threehalfs - ( x2 * y * y ) ); // 1st iteration// y = y * ( threehalfs - ( x2 * y * y ) ); // 2nd iteration, this can be removed
return y;}The casts *(long *)&y and *(float *)&i violate C’s strict-aliasing rules, and long isn’t guaranteed to be 32 bits. This was the idiomatic hack in 1999, but modern compilers may miscompile it. A portable version uses memcpy or C++20’s std::bit_cast with uint32_t.
This function calculates , the inverse square root, without using a square root or division. It appeared in the Quake III Arena source code released by id Software in 2005. Since every polygon needed normalized surface normals for lighting, it required dividing a vector by its magnitude: . On a Pentium II, fsqrt took roughly 69 cycles and fdiv another 38. This function replaced both with integer shifts, a subtraction, and a multiply, roughly 4x faster than the naive path
[lomont-2003]
.
IEEE 754 As a Logarithm
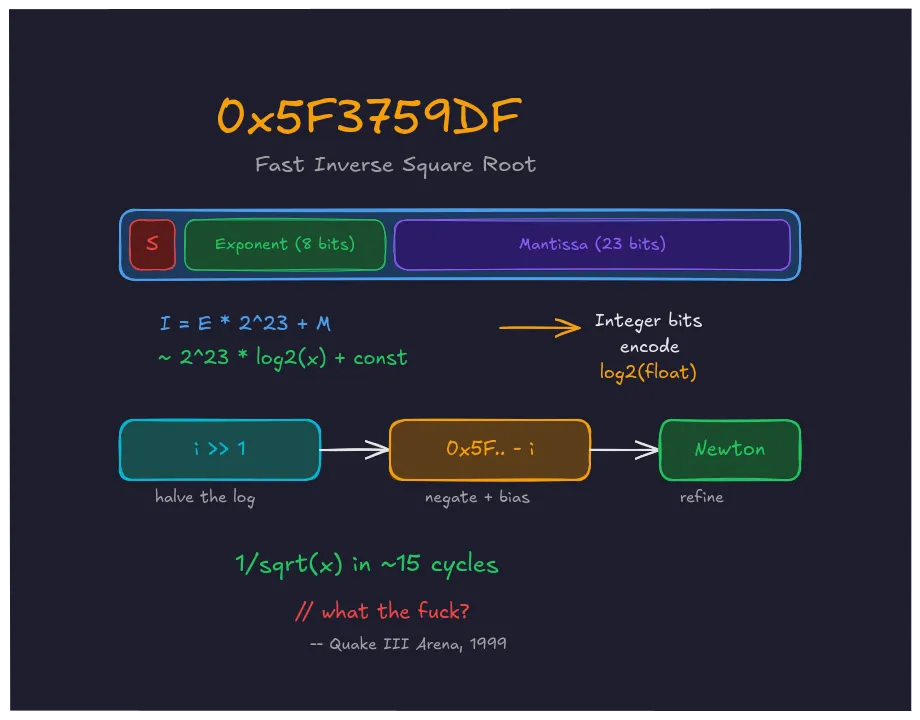
The trick used in Quake exploits a property of IEEE 754 that most programmers will never interact with. A 32-bit float is stored as three fields:
block-beta
columns 3
S["Sign\n1 bit"] E["Exponent\n8 bits"] M["Mantissa\n23 bits"]
style S fill:#4a1942,stroke:#8c2a7a,color:#fff
style E fill:#2d5016,stroke:#4a8c2a,color:#fff
style M fill:#1a1a2e,stroke:#4a4a6a,color:#fff
A positive, normal float represents the value:
Here, is the 8-bit exponent (biased by 127) and is the 23-bit mantissa. The sign bit is zero for positive numbers, which is what matters for inverse square roots.
If you reinterpret those 32 bits as an integer, which is what *(long *)&y does, you get:
The exponent sits in the high bits. The mantissa fills the low bits. And this integer value has an interesting property: it approximates a scaled, shifted logarithm of the float.
To see why, take of the float’s value:
For small values of , . So:
Multiply both sides by :
The integer representation of a float is a scaled logarithm of its value, offset by a constant. This falls directly out of how IEEE 754 encodes the exponent.
And if you want :
Negation and halving, both done with integer arithmetic.
0x5F3759DF
The line that earned the comment “what the fuck?” does the entire inverse square root in log space:
i = 0x5f3759df - ( i >> 1 );i >> 1 right-shifts the integer by one bit. Since the integer approximates , this halves the logarithm, equivalent to taking a square root. The subtraction from the constant negates it, giving the inverse. And 0x5F3759DF itself calibrates the bias.
The math predicts the constant should be = 0x5F400000. But that assumes the approximation is exact, which it isn’t. The real relationship is slightly concave, and the approximation overshoots by varying amounts depending on . The constant 0x5F3759DF compensates for this by shifting down from the naive value to reduce the worst-case error across all positive floats.
After this line runs, y = *(float *)&i reinterprets the integer as a float. This gives a rough first approximation of with a worst-case error around 3.4%.
Newton’s Method
A 3.4% error isn’t good enough for lighting, so Newton-Raphson iteration improves it.
We want such that , which means . Newton’s iteration formula is:
With and :
That last formula matches the code:
y = y * ( threehalfs - ( x2 * y * y ) ); // 1st iterationHere, threehalfs = 1.5F and x2 = number * 0.5F. One iteration involves three multiplies and a subtraction. This reduces the error from 3.4% to under 0.175%
[robertson-invsqrt]
. A second iteration, commented out in the original code, would lower it below 0.0005%. But id Software decided one iteration was enough for lighting normals.
Speed
Each method trades accuracy for cycles. Here are the approaches rewritten with portable memcpy casts and uint32_t:
#include <stdint.h>#include <string.h>#include <math.h>
// 1. Standard library — exact, but ~107 cycles on PIIfloat std_rsqrt(float x) { return 1.0f / sqrtf(x);}
// 2. Q_rsqrt — original Quake III constantfloat q_rsqrt(float number) { float x2 = number * 0.5f, y = number; uint32_t i; memcpy(&i, &y, sizeof(i)); i = 0x5f3759df - (i >> 1); memcpy(&y, &i, sizeof(y)); y *= 1.5f - x2 * y * y; // Newton step 1 // y *= 1.5f - x2 * y * y; // Newton step 2 (optional) return y;}
// 3. InvSqrt3 — optimized constant + tuned Newton coefficients// (Walczyk, Moroz, Cieśliński 2021)float inv_sqrt3(float number) { float y = number; uint32_t i; memcpy(&i, &y, sizeof(i)); i = 0x5f200000 - (i >> 1); memcpy(&y, &i, sizeof(y)); y *= 1.68191391f - 0.703952009f * number * y * y; // tuned NR // y *= 1.50000037f - 0.500000053f * number * y * y; // step 2 return y;}
// 4. SSE rsqrtss intrinsic (Pentium III+)#include <xmmintrin.h>float sse_rsqrt(float x) { return _mm_cvtss_f32(_mm_rsqrt_ss(_mm_set_ss(x)));}The tradeoff on late-1990s hardware [fog-instruction-tables] :
| Method | NR Steps | Max Relative Error | Est. Latency (PII/III) |
|---|---|---|---|
1.0f / sqrtf(x) | — | exact | ~107 cycles |
Q_rsqrt (0x5F3759DF) | 0 | 3.4% | ~5 cycles |
Q_rsqrt (0x5F3759DF) | 1 | 0.18% | ~10–15 cycles |
Q_rsqrt (0x5F3759DF) | 2 | 0.0005% | ~20 cycles |
InvSqrt3 (0x5F200000) | 1 | 0.065% | ~10–15 cycles |
InvSqrt3 (0x5F200000) | 2 | 0.00003% | ~20 cycles |
SSE rsqrtss | 0 | 0.037% | ~2 cycles |
SSE rsqrtss + NR | 1 | ~exact | ~7 cycles |
For the same ~10–15 cycle cost, InvSqrt3’s tuned Newton coefficients cut the error from 0.18% to 0.065%
[walczyk-2021]
. With two steps, it reaches , roughly 12x more accurate than the original at two steps
[robertson-invsqrt]
. For surface normal lighting, where the human eye can’t distinguish 0.18% error from zero, even the original single-step version was more than enough.
The x87 FPU was the only option on Pentium and Pentium II processors. fsqrt alone took ~69 cycles, and you still needed fdiv for the reciprocal. Q_rsqrt replaced all of that with integer operations and a single float multiply chain. On hardware where every cycle mattered for hitting 60 FPS, this was the difference between shipping the game or not.
SSE’s rsqrtss landed with the Pentium III in 1999, the same year Quake III shipped. It provided a hardware inverse-square-root estimate in ~2 cycles with ~12 bits of mantissa precision. But SSE adoption took years, and the Pentium II installed base was massive. Q_rsqrt bridged the gap.
Refining the Constant
How the constant 0x5F3759DF was originally determined is not known precisely — Greg Walsh, who wrote it, never published his derivation. All later refinements have been analytical.
Chris Lomont (2003) exhaustively analyzed the error function and derived a theoretically optimal constant: 0x5F375A86
[lomont-2003]
. After one Newton iteration, it produces a maximum relative error of 0.175124%, compared with the original’s 0.175228%. Marginally better on paper. But Lomont noted something odd: for certain input distributions, the original constant produced lower error after Newton iteration than his “optimal” one. The constant and the iteration step interact in ways that pure minimization of the initial approximation doesn’t capture.
Jan Kadlec (2010) tried a different approach. Instead of just optimizing the constant, he adjusted the Newton-Raphson coefficients by tweaking the 1.5 and 0.5 multipliers. This gave about 2.7 times better accuracy with the same number of iterations.
Walczyk, Moroz, and Cieśliński (2021) took the idea further
[walczyk-2021]
. Their InvSqrt3 simultaneously optimizes the magic constant and the Newton-Raphson coefficients, replacing 1.5 and 0.5 with values tuned for the bit-hack’s specific error distribution. The results are in the table above.
Double precision needs a different constant. Lomont extended the method to 64-bit floats using 0x5FE6EC85E7DE30DA, but because of the wider mantissa, 3 to 4 Newton iterations are needed to get close to machine precision.
Death by Hardware
SSE’s rsqrtss instruction came out the same year as Quake III. It performs the inverse square root in under 5 cycles with 12 bits of precision. Adding one Newton-Raphson step after rsqrtss achieves full float accuracy faster than Q_rsqrt ever could.
Modern GPUs have dedicated inverse square root units built into their shader cores. What once needed a legendary hack now takes just one clock cycle in hardware.
You’d be hard-pressed to find Q_rsqrt in a mainstream engine today. However, the insight that IEEE 754 bit patterns encode logarithmic relationships exploitable by integer arithmetic is not.